Alfresco Disaster Recovery Solution
Our previous blog (Alfresco Repository Clustering) gave you an insight into using alfresco clustering as a means of having an alfresco system with high availability and performance through clustering.
In this blog we will describe two patterns for HA / Disaster Recovery (DR) if you do not have the option of clustering or, if you need a DR instance in a different geographical location.
(Note: These methods can also be used for additional levels of DR in conjunction with the clustered architecture from the previous blog.)
Disaster Recovery involves pushing your repository data to a separate location that can be used in the event of a loss of the primary production data. The SLA for data recovery in DR will determine how you backup data to the DR environment. The following two options will be covered in this blog:
- Delayed Recovery: Scheduled backups with loss of up to one day of data.
- Real-time Recovery: Continuous backup with minimum loss of data.
In both methods the DR Alfresco server software is not running to prevent simultaneous updates of the repository by the DR server.
Delayed Recovery
For this method we will use two Alfresco instances, one in production and one in DR. Backups will occur on a schedule (we use nightly at one of our customers) such as daily, weekly etc. The production Alfresco server is stopped prior to backup and the DB and Data are copied to the DR server as one bundle. It is important that the Alfresco server is stopped to ensure data integrity between the DB and data. Rsynch is used to copy the data directories and mysqldump is used to copy the production db. These are both run by a bash script on a schedule by cron job. The details on how to configure this are below:
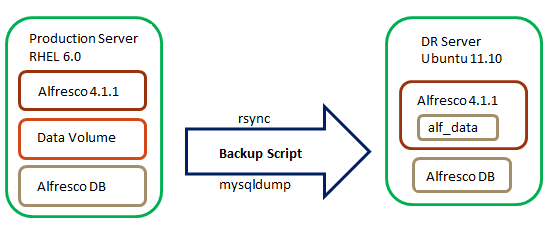
Backup Process
We created a bash executable file called alfresco_backup_rotate.sh, which is executed by a CRON job every night at 1:00 am. The backup script is made of two main components which are mysqldump and rsync. The mysqldump command is used to backup the database and the rsync command is used for moving and synchronizing the db dump and any data from the alf_data source to the target.
The script creates a backup log file called alfresco_backup_(date).log and is stored in /data/backup/logs directory and the option to email this log file is also included.
Script Steps
· The first task of the script is to stop the alfresco server on the source or Prod server and to make sure this is complete, there is a timer set to 5 minutes.
· A database dump is then created of the MySQL alfresco database. The mysqldump command triggers the backup process. Any errors are logged to the log file mentioned above. The dumped database file is created as alfresco_db_dump.sql on the source and then moved to the target using RSYNC.
· Before moving to the RSYNC part, it is ensured that mysqldump has completed its task by checking whether return code of mysqldump is 0.
· If DB dump has been successful, the RSYNC synchronizes the backed up file to the desired target location on the DR server.
· Once the RSYNC for the database is complete, the second RSYNC process is run.
This consists of moving the alfresco alf_data files to the desired target folder on the DR server. And based on the return code of the RSYNC, the success or failure of the process is outputted.
· Before the Alfresco server on the source/Prod server is restarted, it is checked that open office is not running.
RSYNC
RSYNC is a fast and extraordinarily versatile file copying tool. It can copy locally, to/from another host over any remote shell, or to/from a remote rsync daemon. It offers a large number of options that control every aspect of its behaviour and permit very flexible specification of the set of files to be copied. It is famous for its delta-transfer algorithm, which reduces the amount of data sent over the network by sending only the differences between the source files and the existing files in the destination. rsync is widely used for backups and mirroring and as an improved copy command for everyday use.
An advantage of using RSYNC is that once the files have been moved to the target destination for the first time, it just moves the modified or added files.
The RSYNC command is used with –exclude-from parameters so that files listed in usr/local/bin/ alfresco-backup-excludes.txt are not included during RSYNC process.
Only changed or new files are moved to the target.
Any files deleted on the source are also deleted on the target.
CRON Details
The crontab command is used to schedule tasks to be executed periodically.
· Type vim /etc/crontab
· Then add the following entry
01*** /usr/local/bin/alfresco_backup_rotate.sh
· And save the changes
Setting up RSYNC to run without password prompt
On Local/Source Machine Terminal (Prod)
· Type ssh-keygen –t dsa
This command creates two keys; a private key called id_dsa and a public key called id_dsa.pub in ~/.ssh directory
Note: When prompted for password, it was left blank
· Then run the following command;
scp ~/.ssh/id_dsa.pub root@DRserverIP:~/.ssh
The scp command is being used to copy the public key to ~/.ssh directory of the Remote/Server machine.
On the Remote/Server Machine Terminal (DR)
· Go to ~/.ssh directory
· Run cat id_dsa.pub >> authorized_keys
Basically we are copying the public key in authorized_keys
· Then Go to /etc/ssh/ssh_config
Use vim to edit the ssh_config file as follows
Change STRICT MODES from YES to NO
· And finally type service ssh restart
Note
The Production server is running RHEL 6 while the DR server is running Ubuntu 11.10
Restore Process
The DR Alfresco server is not meant to be running until after the restore. In order to restore you need to import the backed up database into the DR MySQL server and point the DR server at the backed up data. The steps are given below:
· From a command prompt on server run the following mysql command:
- mysql –uroot –p alfresco < /data/backup/db/db/alfresco_db_dump.sql
Point the alfresco server to the backed up alf_data.
- vim /opt/alfresco/tomcat/shared/classes/alfresco-global.properties
Update the data directory as follows
- dir.root=/data/backup/alf_data
· Restart Alfresco server
· Monitor logs to ensure it started successfully.
· Ensure you can log into alfresco DR.
Realtime Recovery
A Realtime Recovery method uses a hot/cold server model. The data from the production alfresco server (hot) is backed up to a cold DR server (ie an Alfresco instance is installed but not running). The DR server is started manually when the production server fails and will automatically pick up the data that has been synched from the production environment.
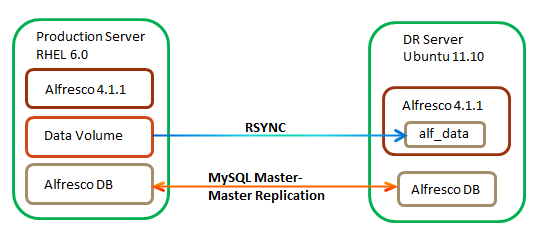
RSYNC Data Replication
As mentioned previously RSYNC is a fast and extraordinarily versatile file copying tool. RSYNC finds files that need to be transferred using a “quick check” algorithm (by default) that looks for files that have changed in size or in last-modified time. Any changes in the other preserved attributes (as requested by options) are made on the destination file directly when the quick check indicates that the file’s data does not need to be updated. The following command is the basic command to push the content data from the Production server to the DR server.
rsync [OPTION…] SRC… [USER@]HOST:DEST
More options can be found on this link (http://www.computerhope.com/unix/rsync.htm).
MySQL DB Replication Setup
It is possible to set up the Production database server and DR database server in a MySQL Master-Master or Master-Slave configuration. Replication allows you to continuously copy a database to a different server.
The advantage of using this architecture is that there is neither need to stop alfresco to back up the db nor any need to restore the db.
To enable replication, you set one server (the slave) to take all its updates from the other server (the master). During replication, no data is actually copied. It is the SQL statements that manipulate the data that is copied.
All statements that change the master database are stored in the master’s binary logs. The slave reads these logs and repeats the statements on its own database. The databases will not necessarily be exactly synchronized. Even with identical hardware, if the database is actually in use, the slave will always be behind the master. The amount by which the slave is behind the master depends on factors such as network bandwidth and geographic location. The other server can be on the same computer or on a different computer. The effect of replication is to allow you to have a nearly current standby server.
Using more than one server allows you to share the read load. You can use two slaves. If one of the three servers fails, you can use one server for service while another server can copy to the failed server. The slaves need not be running continuously. When they are restarted, they catch up. With one or more slaves you can stop the slave server to use a traditional backup method on its data files.
Master – Slave MySQL replication is the process by which a single data set, stored in a MySQL database, will be live-copied to a second server (one –way replication from master to slave).
Master – Master MySQL replication allows data to be copied from either server to the other one. This subtle but important difference allows us to perform MySQL read or writes from either server. This configuration adds redundancy and increases efficiency when dealing with accessing the data.
Details on how to set up MySQL replication can be found on this link (https://www.digitalocean.com/community/articles/how-to-set-up-mysql-master-master-replication).
Reference:
- http://linuxwave.blogspot.com.au/2007/07/ssh-without-password.html
- http://troy.jdmz.net/rsync/index.html
- http://theos.in/shell-scripting/send-mail-bash-script/
- http://www.computerhope.com/unix/rsync.htm
- https://www.digitalocean.com/community/articles/how-to-set-up-mysql-master-master-replication